今まで、Schedule Workflowを使って複数のデータをループ処理することはよくしていたのですが、一度に登録するデータ量があまり多くなかったので、再帰的処理を使うことはありませんでした。
しかし、ドキュメントには再帰的処理をして大量のデータを登録することが書かれています。
対象のデータを処理している場合、変更に時間がかかりすぎると、…タイムアウトになる可能性があります。
bubble document
でもこのページサンプルないの…。
言いたいことはわかるけどサンプルくらい見せてよ😭
ということで作ってみました、じゃん。
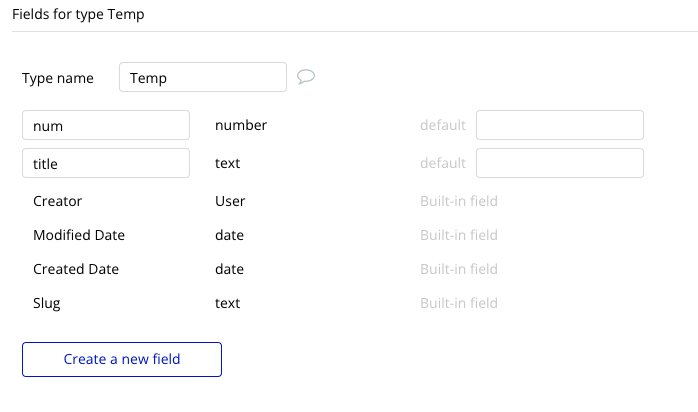
DBを作る
ここではサンプルなので、DBを2つ用意して、 DB1→DB2にコピーします。
結構実務でも使うんですが、CSV登録するときに「存在したら更新、存在しなければ新規作成。」といった実装があるんですね。bubbleのUpload data as CSVアクションは全て新規登録してしまうので、一時テーブルに保存させ、一時テーブルの値を本テーブルにコピーするような形で使っています。
今回は単純なコピーなので、2つのテーブルの構成は同じです。
DBに適当な値を登録しておく
ここで、コピーする対象のデータを適当に登録しておきます。50件作成しました。割愛😅
再帰的ワークフローを組む
本題の再帰的ワークフローですが、今回は「Bulk」と名前をつけました。お好きにどうぞ。
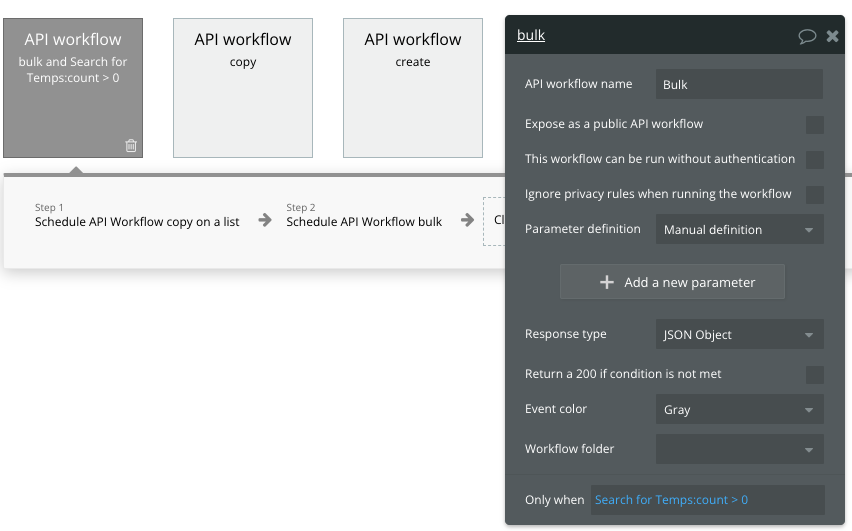
組むワークフローの内容ですが、以下のようにしてみました。
- Tempのデータのうち10件に対して、Schedule workflow on a listを実行。1データごとに5秒のinterval
- 5分後に1を再度実行
ここでは、TempをTemp2にコピーしたらTempを削除しています。そのため、実行条件に「Temp:count>0」を入れています。削除されてデータがなければ実行する必要がないからですね。
Schedule workflow on a listについては、別のSchedule workflow(copy)を呼び出して、intervalを5秒に設定しています。このとき、実行対象のリストは Search for Tempの10件分を指定しています。
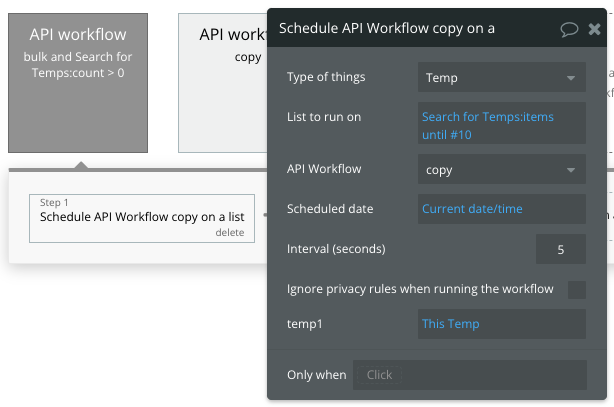
2つめのアクションで、5分後に自分自身を呼び出しています。
こうすることで、5分ごとに自分自身が呼び出されます。これが再帰的の部分!

処理内容を組む
最初のアクションで、リストでSchedule workflowを呼んだのでその内容を書いておきます。
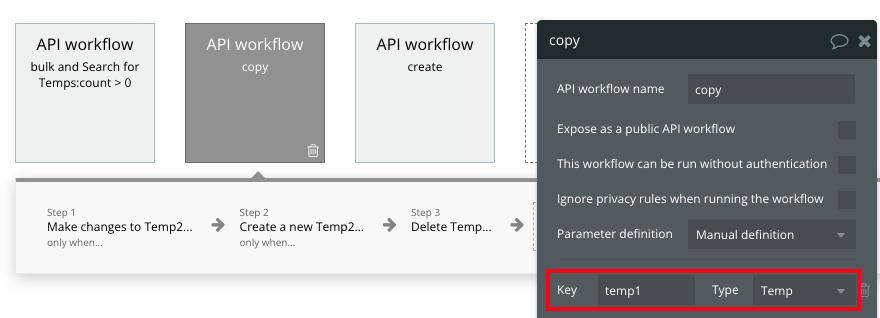
Schedule workflowの引数は、コピー元Tempのデータです。
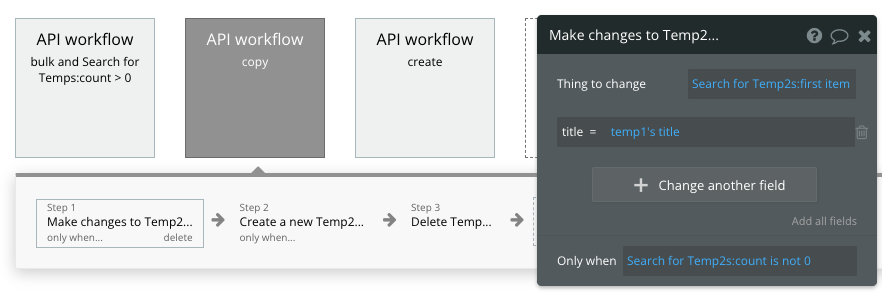
最初にTemp2に同じnumberを持つデータがあれば、更新する処理を設定します。
次に、Temp2に同じnumberを持つデータがなければ、新規作成する処理を設定します。
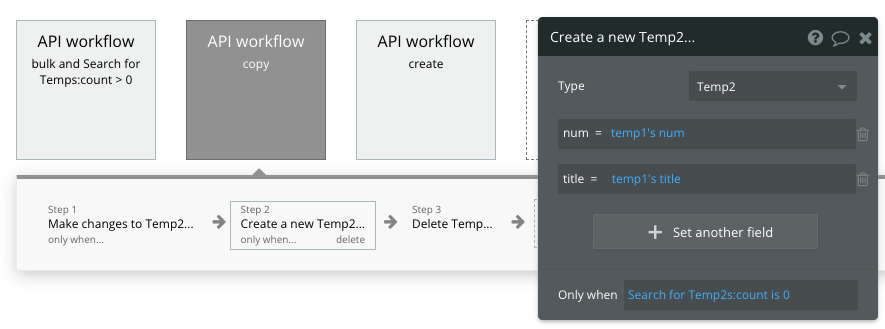
順番は「更新処理」「新規作成処理」にしましょう!
最初のころ何回かやっちゃったんですが、、、「新規作成処理」「更新処理」にしてしまうと、新しいレコードを作って更新するという2重の処理が走ってしまいます。。😭
最後に、コピー元Tempのデータを削除します。
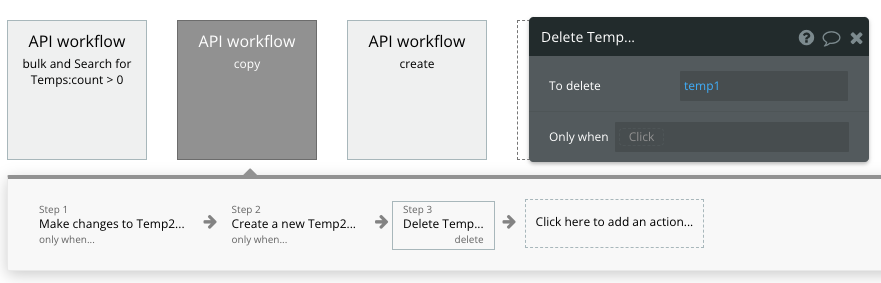
コピー元データの削除をやるのは色々理由がありますが、1つ大きな理由があります。そしてよく使います。
Backend Workflowの実行完了について、画面上で取得できない😱
これ結構困るんですよね。100件以上のデータをCSVで更新したときに、更新完了を知りたいんですよ、画面上で。
もちろん、完了時にメールを送るとかの代替案もありますけど。
なので、よくやるのは、CSVアップロードの時間を取得しておいて、Tempテーブルにその時間以降に作成されたデータが0件になったら完了ポップアップを出すという処理です。Do when condition is trueトリガーで設定しています。
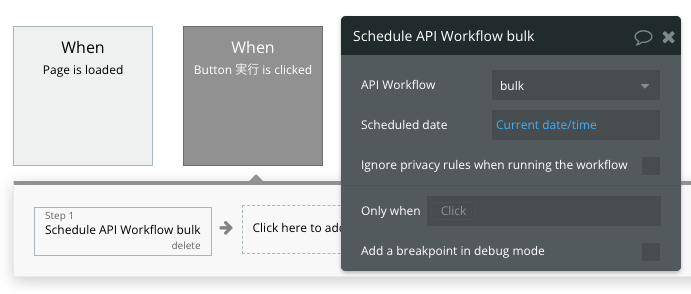
実行開始ボタンを設置する
最後に、設定したbulkを実行開始するためのボタンを配置します。
ほんとにボタンだけです…。

そして、ボタンクリック時に先ほど設定した再帰的ワークフローを呼び出します。
プレビューしてみる
さて、それでは実行ボタンをクリックして、データがコピーされるところをDB画面で眺めてみます。
ここでは最初の10件しか収録していませんが、10件目が登録終わったあとに11件目がすぐ作られていないのがわかると思います。
5分後に、再度11〜20が作られることが確認できますので、気長に待ってみてください。
ある程度処理が終了した段階で、こんな感じになっています。
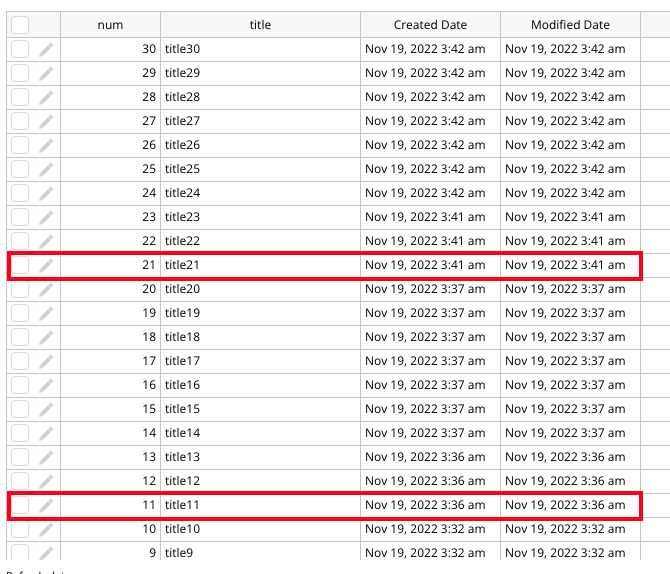
5分ごとに開始されているのがわかりますね。
こんな感じで、再帰的ワークフローを組むことができました。
明示的なループ処理は存在しませんが、工夫次第で色々できるのがbubbleの楽しいところかなと個人的には思います。